UNIX-подобные операционные системы являются
многопользовательскими. Пользователи и группы в которых они состоят
используются для управления доступом к системным файлам, каталогам и
периферии. По умолчанию linux предлагает относительно простые механизмы
контроля доступа. Расширить их можно при помощи LDAP и ACL, но в этой
теме мы рассмотрим стандартные средства контроля допуска.
Под каждого пользователя, создается свой каталог (home directory). В этот каталог попадает пользователь, после того как он авторизировался и в нем храниться личные файлы и папки пользователя. Все каталоги пользователей собраны в одном месте, обычно это /home.
Также, пользователю назначается командная оболочка (командный интерпретатор, используемый в операционных системах семейства UNIX). Например: /bin/bash, /bin/zsh, /bin/sh и.т.д. У многих дистрибутивов linux, для пользователей, по умолчанию назначается командная оболочка bash.
Каждому пользователю назначается идентификационный номер (User ID). Сокращенно номер обозначается как UID, является уникальным идентификатором пользователя. Операционная система отслеживает пользователя именно по UID, а не по их имени.
Также, каждому пользователю назначается пароль для входа в систему. Пароль храниться в зашифрованном виде (encripted). Для создания и изменения пароля используется команда passwd. Системный администратор может сам назначить пароль или дать возможность пользователю ввести свой пароль при первой авторизации.
Каждый пользователь принадлежит минимум к одной или нескольким группам. (пользователи и группы в linux)
Каждой группе назначается идентификационный номер (group ID). Сокращённо GID, является уникальный идентификатором группы. Принадлежность пользователя к группе устанавливается администратором.
Вывод может быть следующий:
Для того, чтобы не вводить эту информацию вручную, существует программа useradd (или adduser). Настройки этой программы хранятся в файле /etc/default/useradd.
Для создания нового пользователя воспользуемся командой useradd:
Если мы хотим заставить пользователя сменить пароль на свой при первом входе в систему нужно применить команду:
Как создать новую группу в Linux
Добавление существующей учетной записи пользователя в группу
Изменение первичной группы пользователя
Как узнать, в какие группы входит пользователь

Создание нового пользователя и назначение группы в одной команде
Добавление пользователя в несколько групп
Как просмотреть все группы в системе
Пользователи и Группы в Linux
Пользователи:
Пользователь - это любой кто пользуется компьютером. Пользователю назначается имя, имя должно быть уникальным в системе (linux есть зарезервированные имена, такие как «root», «hal», и «adm»). Имя может состоять из букв английского алфавита, арабских чисел и символов «_»(нижний пробел) «.»(точка).Root (от англ. root — корень; читается «рут»), суперпользователь — это аккаунт в UNIX-подобных операционных системах с идентификатором (UID) 0, владелец этого аккаунта имеет право на выполнение любой операции. В целях безопасности работать под суперпользователем root не рекомендуется.Помимо системного имени, в систему может занестись и хранится полное имя (например Ф.И.О)(full name) реального пользователя. Например, пользователю newuser в реальной жизни может соответствовать человек по имени John Smith. Эта информация позволит лучше контролировать и идентифицировать пользователей системному администратору, тем более, если пользователей в системе сотни или даже тысячи.
Под каждого пользователя, создается свой каталог (home directory). В этот каталог попадает пользователь, после того как он авторизировался и в нем храниться личные файлы и папки пользователя. Все каталоги пользователей собраны в одном месте, обычно это /home.
Также, пользователю назначается командная оболочка (командный интерпретатор, используемый в операционных системах семейства UNIX). Например: /bin/bash, /bin/zsh, /bin/sh и.т.д. У многих дистрибутивов linux, для пользователей, по умолчанию назначается командная оболочка bash.
Каждому пользователю назначается идентификационный номер (User ID). Сокращенно номер обозначается как UID, является уникальным идентификатором пользователя. Операционная система отслеживает пользователя именно по UID, а не по их имени.
Также, каждому пользователю назначается пароль для входа в систему. Пароль храниться в зашифрованном виде (encripted). Для создания и изменения пароля используется команда passwd. Системный администратор может сам назначить пароль или дать возможность пользователю ввести свой пароль при первой авторизации.
Каждый пользователь принадлежит минимум к одной или нескольким группам. (пользователи и группы в linux)
Группы:
Для разграничения прав в linux, помимо пользователей, существуют группы. Так же как и пользователь, группа обладает правам доступа к тем или иным каталогам, файлам, периферии (в системе есть зарезервированные группы). Для каждого файла определён не только пользователь, но и группа. Группы группируют пользователей для предоставления одинаковых полномочий на какие-либо действия.Каждой группе назначается идентификационный номер (group ID). Сокращённо GID, является уникальный идентификатором группы. Принадлежность пользователя к группе устанавливается администратором.
Просмотр пользователей
(пользователи и группы в linux) Вся вышеизложенная информация хранится в файле /etc/passwd. Чтобы посмотреть список пользователей нужно ввести команду:# cat /etc/passwdКаждый аккаунт занимает одну строку. Вывод может быть следующим:
root:xD928Jhs7sH32:0:0:root:/root:/bin/bash
newuser:Xv8Q981g71oKK:1000:100:John Smith:/home/newuser:/bin/bash
Эта строки имеет следующий формат:account:password:UID:GID:GECOS:directory:shell
где:Для просмотра списка пользователей которые находятся в данный момент времени в системе есть команда who.account— имя пользователяpassword— зашифрованный пароль пользователяUID— идентификационный номер пользователяGID— идентификационный номер основной группы пользователяGECOS— необязательное поле, используемое для указания дополнительной информации о пользователе (например, полное имя пользователя)directory— домашний каталог ($HOME) пользователяshell— командный интерпретатор пользователя (обычно/bin/sh)
Вывод может быть следующий:
newuser pts/0 2013-11-13 14:19 (:0)
Создание, управление и удаление пользователей
(пользователи и группы в linux) При создании новых пользователей совершается последовательность определенных действий. Сначала заводится запись в файле /etc/passwd, где пользователю назначается уникальное имя, UID, GID и другая информация. UID должен быть больше 1000, а GID более 100, это связано с тем, что система резервирует маленькие значения под свои нужды. Также, создается каталог, устанавливаются права, помещаются файлы инициализации командной оболочки и модифицируются конфигурационные файлы.Для того, чтобы не вводить эту информацию вручную, существует программа useradd (или adduser). Настройки этой программы хранятся в файле /etc/default/useradd.
# cat /etc/default/useraddВывод следующий:
GROUP=100
HOME=/home
INACTIVE=-1
EXPIRE=
SHELL=/bin/bash
SKEL=/etc/skel
CREATE_MAIL_SPOOL=no
В нем можно изменить параметры по умолчанию. Например, директорию для пользователей с /home на /home/user или интерпретатор с /bin/bash на /bin/sh.Для создания нового пользователя воспользуемся командой useradd:
# useradd -m -g users -G audio,lp,optical,storage,video,wheel,games,power,scanner -s /bin/bash newuserРасшифровка:
# useradd -m -g [основная группа] -G [список дополнительных групп] -s [командный интерпретатор] [имя пользователя]
-m— создаёт домашний каталог, вида/home/[имя пользователя].-g— имя или номер основной группы пользователя.-G— список дополнительных групп, в которые входит пользователь.-s— определяет командную оболочку пользователя.
# man useraddКомандой chfn можно внести или изменить информацию учетной запеси пользователя (ФИО, рабочий телефон, рабочие координаты и.т.д)(username — имя пользователя).
# chfn [-f полное-имя][-о office][-p рабочий-телефон][-h домашний-телефон][-u][-v][username]Для задания пароля используется команда passwd:
# passwd [username]Далее, нам будут предложено ввести новый пароль и повторить его.
Если мы хотим заставить пользователя сменить пароль на свой при первом входе в систему нужно применить команду:
# chage -d 0 [username]Более подробно о команде chage можно почитать в мануале, введите:
# man chageДля того, чтобы удалить пользователя существует команда userdel
# userdel -r [username]Параметр -r указывает на то, что следуют вмести с пользователем удалить домашнею директорию и почтовый ящик.
Управление группами
Для просмотра всех групп системы и каким пользователем они принадлежат нужно ввести следующее:# cat /etc/groupФайл /etc/group определят группы в системе. Чтобы посмотреть в каких групах состоит пользователь нужно набрать:
# groups [username]Команда id показывает более подробную информацию.
# id [username]Для создание новой группы:
# groupadd [group]Чтобы занести пользователя в группу:
# gpasswd -a [user] [group]Вывод пользователя из группы:
# gpasswd -d [user] [group]И для того, чтобы удалить группу, введем следующие:
# groupdel [group](пользователи и группы в linux) На этом в принципе все, самое основное изложено.
Как в Linux добавить пользователя в группу (или вторичную группу)
Учетные записи пользователей могут быть назначены одной или нескольким
группам в Linux. Вы можете настроить права доступа к файлам и другие
привилегии по группам. Например, на Ubuntu только пользователи из группы
sudo могут использовать команду sudo для получения повышенных
разрешений.
Как создать новую группу в Linux
Если вы хотите создать новую группу в своей системе, используйте команду groupadd, заменив new_group на имя группы, которую вы хотите создать. Вам также нужно будет использовать sudo с этой командой (или в дистрибутивах Linux, которые не используют sudo, вам нужно будет запустить команду su, чтобы получить повышенные разрешения перед запуском команды).
1
| sudo groupadd new_group |
Добавление существующей учетной записи пользователя в группу
Чтобы добавить существующую учетную запись пользователя в группу в вашей системе, используйте команду usermod, заменив group_name на имя группы, в которую вы хотите добавить пользователя, в user_name на имя пользователя, которого хотите добавить.
1
| usermod -a -G group_name user_name |
Например, для добавления пользователя mial в группу sudo, используйте следующую команду:
1
| usermod -a -G sudo mial |
Изменение первичной группы пользователя
Хотя учетная запись пользователя может входить в нескольких групп, одна
из групп всегда является «основной группой», а остальные являются
«вторичными группами». Процесс входа пользователя, файлы и папки,
созданные пользователем, будут назначены первичной группе.
Чтобы изменить основную группу, которой назначен пользователь, запустите команду usermod, заменив group_name на имя группы, а user_name на имя учетной записи пользователя.
1
| usermod -g group_name user_name |
Обратите внимание здесь на -g. Когда вы используете маленькую g, вы назначаете главную группу. Когда вы используете заглавную -G , как в примерах выше, вы назначаете вторичную группу.
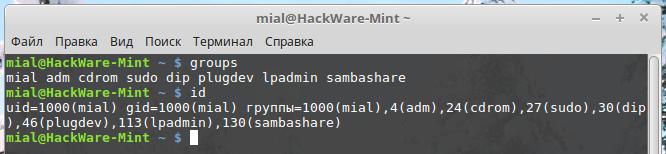
Как узнать, в какие группы входит пользователь
Чтобы просмотреть группы, которым назначена текущая учетная запись пользователя, выполните команду groups. Вы увидите список групп.
1
| groups |
Чтобы просмотреть числовые идентификаторы, связанные с каждой группой, выполните команду id:
id
Для просмотра групп в которые входит другая учетная запись
пользователя, запустите команду groups и укажите имя учетной записи
пользователя.
1
| groups user_name |
Вы также можете просмотреть числовые идентификаторы, связанные с каждой группой, запустив команду id и указав имя пользователя.
1
| id user_name |
Первой группой в списке групп или группой, показанной после «gid=»
в списке идентификаторов, является первичная группа учетной записи
пользователя. Другие группы – это вторичные группы. Итак, на скриншоте
ниже основной группой учетной записи пользователя является mial.
Создание нового пользователя и назначение группы в одной команде
Иногда вам может понадобиться создать новую учетную запись
пользователя, которая имеет доступ к определенному ресурсу или каталогу,
например, новому пользователю FTP. С помощью команды useradd при
создании учетной записи пользователя вы можете указать группы, которым
будет назначена учетная запись пользователя, например:
1
| useradd -G group_name user_name |
Например, чтобы создать новую учетную запись пользователя с именем jsmith и назначить эту учетную запись группе ftp, вы должны запустить:
1
| useradd -G ftp jsmith |
Конечно, вы захотите назначить пароль для этого пользователя:
1
| passwd jsmith |
Добавление пользователя в несколько групп
Вы можете добавить пользователя сразу в несколько вторичных групп, разделив список запятой:
1
| usermod -a -G group1,group2,group3 user_name |
Например, чтобы добавить пользователя с именем mial в группы ftp, sudo и example, вы должны запустить:
1
| usermod -a -G ftp,sudo,example mial |
Вы можете указать столько групп, сколько хотите – просто разделите их все запятой.
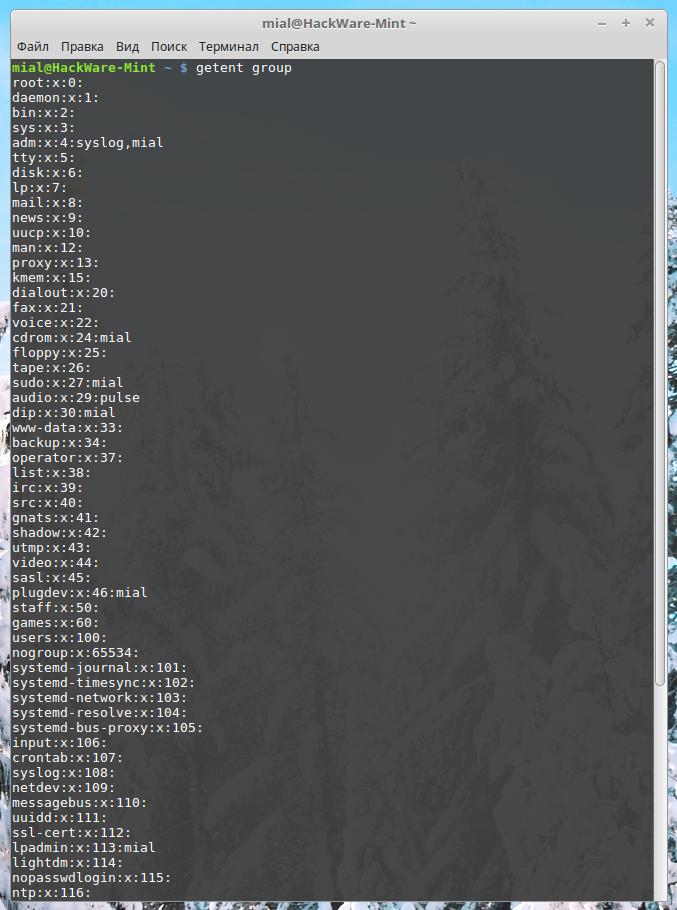
Как просмотреть все группы в системе
Если вы хотите просмотреть список всех групп в вашей системе, вы можете использовать команду getent:
1
| getent group |
Этот вывод также покажет вам, какие учетные записи пользователей
являются членами групп. Итак, на скриншоте ниже мы видим, что учетные
записи пользователей syslog и mial являются членами группы adm.
Это должно охватывать все, что вам нужно знать о добавлении пользователей в группы в командной строке Linux.